High availability for intra city cross availability zone in private cloud
本文主要对专有云同城跨AZ高可用场景做简要的技术介绍。
高可用架构介绍
专有云产品的底座,是一个基于kubernetes和容器的产品,所以这里介绍的同城多AZ方案,首先是底座要有多AZ能力。kubernetes相关组件和自带的中间件,如RabbitMQ、ETCD、MySQL等,都需要支持跨AZ的多副本实例。一般的,业务容器无状态的多副本应用均匀分布在多AZ,中间件实例由于是有状态的而且存在选主,通常是 2:1 或者 3:2 的数量比例分布在两个AZ中。如果是3AZ的话,数量比例可以是 1:1:1 或者 2:2:1。如下表所示:
| 副本分布策略 | 有状态的 | 无状态 |
|---|---|---|
| 双AZ | AZ1:AZ2:AZ3 = 2:1 或 3:2 | 选择副本最少的AZ |
| 三AZ | AZ1:AZ2:AZ3 = 1:1:1 或 2:2:1 | 选择副本最少的AZ |
备注:为了保障跨AZ服务的可用性和稳定性,要求AZ间的网络延迟 <= 5ms (如果不满足此延迟条件,说明两个机房不在同城同地域,按照异地跨 Region 来看,跨 Region 的高可用方案不在文本中讨论)
同城双AZ高可用说明
主可用区承载了本地域绝大部分的计算存储路由等能力,主可用区服务异常将会影响到本地域内其他可用区的服务稳定性,影响较大。备可用区承载了本地域绝大部分的关键数据的副本,备可用区服务异常会导致主备数据同步异常、备份数据异常等情况,对本地域内其他可用区的服务稳定性有影响,影响较小,恢复速度快。
为保证备可用区故障时,集群的可用性不受影响,所以分布式集群的多数节点都部署到主可用区。当主可用区故障时,备可用区中少数节点无法提供服务,需要在备可用区重建集群,恢复服务。
底座的必要且重要的三个模块:容器平台模块、对象存储模块、负载均衡网关模块。所以本文讨论这三个模块的高可用。
2.1 双AZ高可用部署架构
双AZ高可用的部署架构如下图所示:
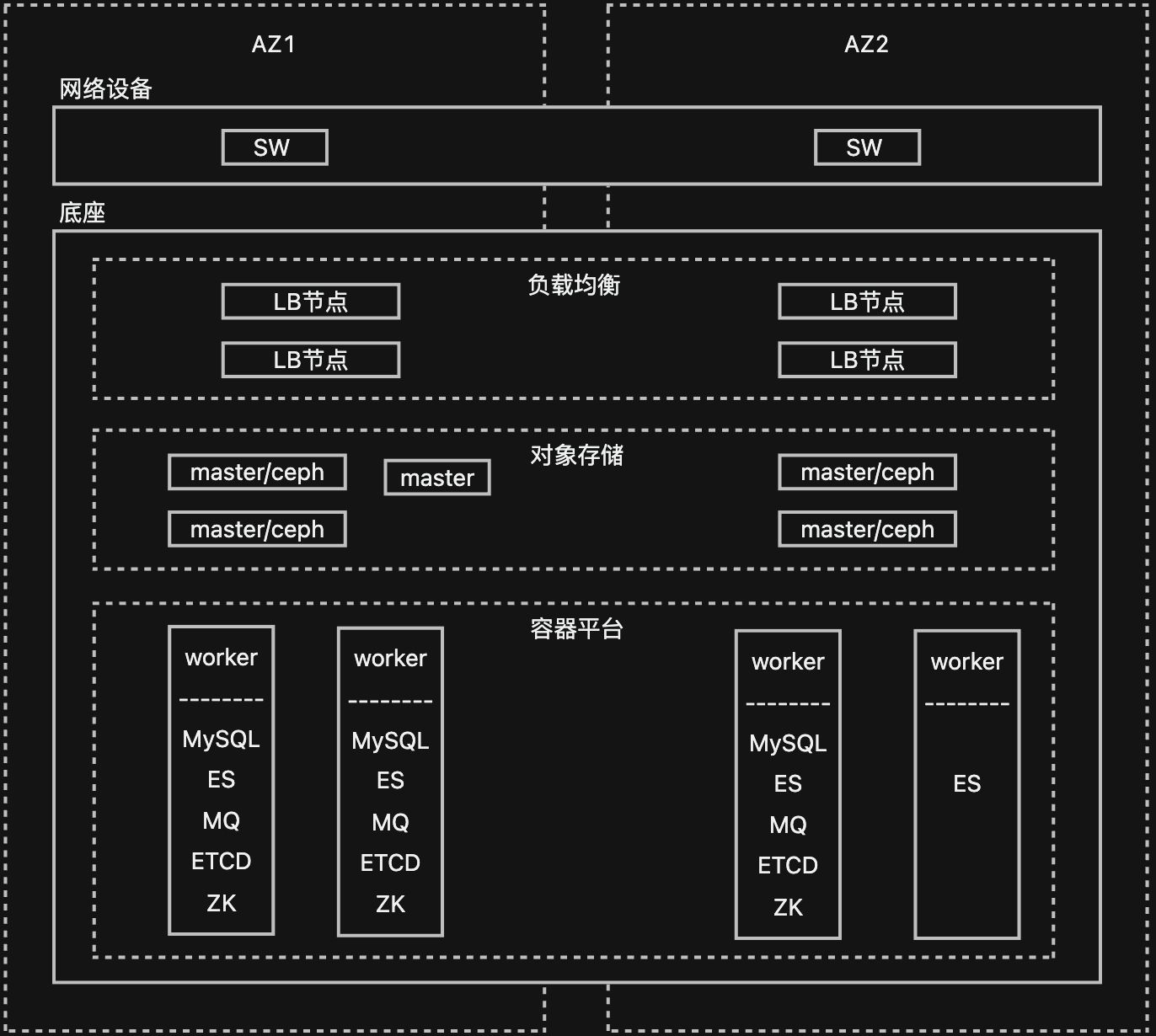
第一层的网络设备。第二层是底座,底座包含上述的三个模块,其中:
- 负载均衡模块有4个LB节点,其中每个AZ两个LB节点;
- 对象存储(如ceph)模块放到4个节点,如上图所示,它和k8s master节点混布,每个AZ选择两个master节点部署对象存储;
- 容器平台模块画的是多种有状态的容器部署情况。例如MySQL部署
2.2 容器平台管控模块
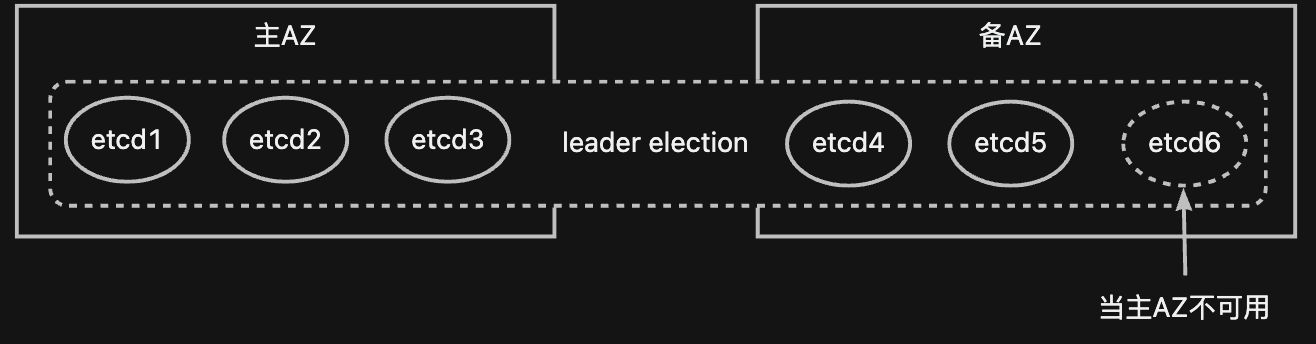
容器平台管控面,简单来讲是kubernetes的高可用部署。它的无状态组件如apiserver、controller等通过kubernetes API进行选主并进行自动切换。因为容器平台的高可用主要关注状态组件etcd的容器部署和故障处理能力。
etcd的双AZ部署数量为 3(主AZ)+2(备AZ),etcd采用的是raft协议,即“多数派”选主协议。当备AZ故障时,etcd集群仍然可用;
当主AZ故障时需要进行切换,在备AZ基于当前数据重新组件集群后提供服务,另外还会在备AZ的其他kubernetes node上再启动一个etcd实例,使得备AZ有一套3实例的etcd集群,可以容忍单点故障。如下图所示:
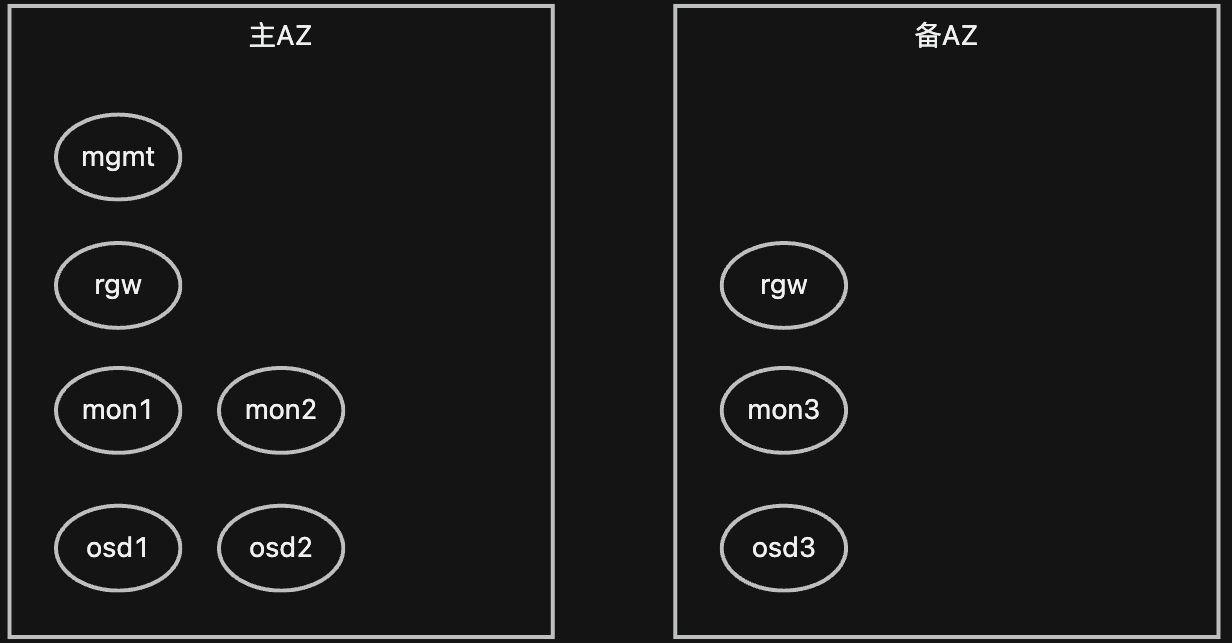
2.3 对象存储模块
对象存储推荐采用ceph的容器化部署方案。可以使用Rook部署架构。当然本文中只是使用它的对象存储能力。部署的架构如下图,有状态是的osd和mon。mon 采用 2:1 架构部署,当备 AZ 故障时,调整最小副本数 CSP 集群整体仍然可用;当主 AZ 故障时需要进行组件切换并调整最小副本数。
2.4 负载均衡网关模块
这块的高可用方案比较多,有空单独说。
高可用的衡量指标
高可用最重要的两个衡量指标,即RTO和RPO。
| 指标 | 全称 | 定义 | 关键问题 | 业务影响维度 |
|---|---|---|---|---|
| RTO | Recovery Time Objective | 系统故障后,可容忍的最大恢复时间(从宕机到恢复服务的时间上限) | “业务要停多久?” | 时间敏感性 |
| RPO | Recovery Point Objective | 系统故障后,可容忍的最大数据丢失量(恢复到故障前哪个时间点的数据状态) | “数据要丢多少?” | 数据完整性 |
按照时间轴顺序,如下图所示:
故障发生时刻:T0
│
├─ 数据丢失窗口 (RPO范围) ──────▶
│ [允许丢失T0前X分钟数据]
│
▼
┌───────────────────────┐
│ 系统不可用期 (RTO范围) │◀─ 允许的最大停机时间Y分钟
└───────────────────────┘
│
▼
业务恢复时刻:T0 + Y (RTO)
我们可以按照上述2.1-2.4的描述,以及高可用方案,可以评估对应的RPO和RTO填入下表。针对不同的客户。
| 组件名称 | RTO | RPO | |
|---|---|---|---|
| 主 AZ 故障 | 备 AZ 故障 | 主 AZ 故障 | |
| 容器平台 | |||
| 对象存储 | |||
| 负载均衡 | |||
| 有状态服务1 | |||
| 有状态服务2 | |||
| 有状态服务3 |
典型系统参考值
| 系统类型 | RPO | RTO |
|---|---|---|
| 金融支付系统 | 0 | ≤ 30秒 |
| 航空订票系统 | ≤ 1秒 | ≤ 2分钟 |
| 医院HIS系统 | ≤ 5分钟 | ≤ 15分钟 |
| 企业CRM | ≤ 1小时 | ≤ 4小时 |
| 学校教务系统 | ≤ 24小时 | ≤ 1工作日 |
故障恢复管理系统
同城双AZ高可用,不仅需要各个组件的高可用的技术方案,并满足客户的RPO和RTO要求。我们还需要有一个故障恢复管理系统,期望实现可用区级别服务的故障恢复:能够满足服务状态可视化、故障探测自动化、切换流程编排白屏化、故障演练日常化,实现服务端到端一键切换,提升容灾演练和故障切换的效率及易用性,帮助客户提升容灾能力。
故障恢复管理系统的一般的步骤如下:
- 可用区故障探测
通过对可用区中的节点定期探活,实现对可用区的探活并发送异常告警,辅助用户进行故障切换的决策。
- 切换能力评估
系统在可用区切换前,通过对产品状态的检查结果,进而对可用区切换能力进行评估,辅助切换决策。
- 故障一键切换
当AZ发生故障时,通过预置的切换流程,将产品在可用的AZ中恢复。为了提高切换效率,系统预置了切换流程,根据产品之间是否存在依赖关系,对切换顺序进行了编排,存在依赖关系的产品执行串行切换,无依赖关系的产品执行并行切换。
受限于部署架构(主 2 备 1),当主 AZ 故障后,系统自身的可用性不能自动恢复,需要执行恢复脚本恢复可用性。
- 故障演练报告
通过汇总演练过程中记录的配置检查结果、产品切换的RTO及执行的结果,提升演练效率。